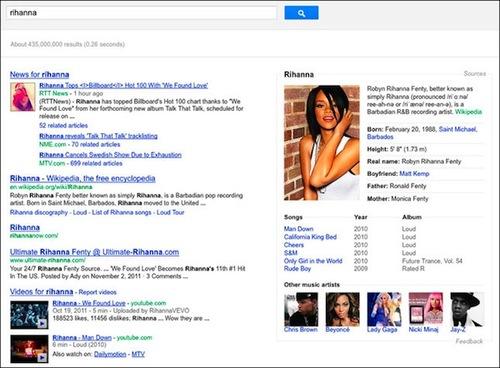
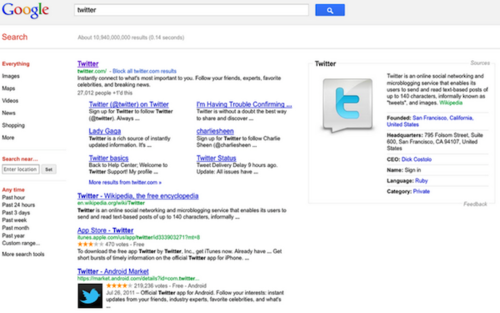
Google teste actuellement un nouveau mode d'affichage des résultats, nommé "Sources", identifié par Cyrus Shepard de SEOMoz. Les résultats proposées sont synthétiques, organisées et sembleraient être les plus importants. Dans les exemples trouvés : pour Twitter, l'URL du site, les personnes les plus populaires sur ce site, un lien vers des tutoriels... pour la chanteuse Rihanna, une mini-bio à la Wikipédia.
Qu'en penser ?
 See the full gallery on Posterous
See the full gallery on Posterous
Frédéric :
Avec ce nouveau mode d'affichage, Google prolonge l'expérimentation de structuration du Web à la volée. Amorcée avec Google Squared, dans lequel Google testait sa capacité à transformer une simple liste de résultats (URLs + abstracts) en résultats homogènes et structurés en fonction de champs et de variables identifiées à la volée, Google va un pas plus loin en proposant une fiche synthétique agrégée à partir de différentes sources.
A une époque fort lointaine, (entre 2003 et 2005 je dirais), le moteur de recherche Tuna Search proposait un mode de visualisation des résultats proche de "Sources" en vous proposant une fiche de synthèse sur une personne, une entreprise ou tout autre type de recherche.
Ce mode de visualisation va à mon avis dans le sens des attentes des utilisateurs grand public et également dans le sens de l'offre de services proposé par les fournisseurs d'informations, infomédiaires, services de curation ou autre en procédant à une éditorialisation de l'information accessible sur un sujet et non plus à une liste de résultats agrémentés d'un extrait.
Au delà, de l'intérêt du gain de temps et de la facilité de lecture et de consultation des résultats, reste la question sur les algorithmes de traitement permettant de valoriser tel ou tel type de résultats dans une fiche de synthèse et de l'impact sur le biais informationnel par la succession d'algorithmes de collecte, de classement dans la liste de résultats et de priorisation dans le processus éditorial (sélection, organisation de l'espace éditorial disponible)
Jérôme :
Cette expérimentation de Google me fait très fortement penser à Bing. Mais là où Bing apporte du contenu enrichit via des partenariats, Google le fait via des algorithmes... Cette approche me fait également penser à une sorte d'ébauche de Qwiki en tentant d'apporter une réponse synthétique à une recherche sur une entité nommée.
C'est une approche très intéressante d'un point de vue utilisateur, mais elle me semble s'approcher dangereusement de la ligne de vampirisation du web par Google. Effectivement, en déportant directement sur la page de résultats des informations factuelles qui aujourd'hui sont proposés par des sites éditoriaux, ces derniers verront leurs visites chuter sur ce type de pages alors qu'ils auront consacré du temps (et donc de l'argent) à constituer ce genre de base de données (base de données d'artistes, de chansons, d'entrepreneurs, etc...) !
Avec ce genre d'approche, Google devient non plus une porte d'entrée sur le Web, mais il devient de plus en plus LE Web. Et je m'interroge de plus en plus sur les types de sites économiquement viables à long terme face à la vampirisation du contenu par Google.
Permalink | Leave a comment »

